我們已經可以找到包含關鍵字的相關文件,但它可能不滿足實際搜索的需求。當搜索引擎需要返回數十萬、甚至上百萬甚至千萬的結果時,我們該如何將最相關的文件顯示在前面呢?
用戶輸入查詢描述
目前,搜索引擎提供自然語言搜索以及布爾運算高級搜索,因此查詢描述也遵循一定的語法結構。例如,我們可以輸入查詢描述"search AND using NOT image",它搜索包含search和using但不包含image的文件。
對查詢描述進行詞法分析、語法分析、語言處理
詞法分析用於分析查詢詞和布爾關鍵詞,上面的查詢描述分析出的查詢詞為search using image,布爾關鍵詞是AND和NOT。語法分析會將詞法分析的結果生成一棵語法樹。上例形成的語法樹如圖所示。語言處理與建立索引時的語言處理過程幾乎相同。
搜索索引,返回符合上述語法樹的結果
首先,在反向索引中分別找出包含search、use和image的文件鍵終屆列。然後,將包含search和use的文件鍵結串列合並,得到既包含search,又包含use的文件鍵結串列。接著,在上一步選擇的結果中去除包含image的文件鏈結串列,最後的文件鏈結串列就是符合上述語法樹的結果。
對結果進行相關性排序
雖然在上一步驟中我們獲得了想要尋找的文件,但這些文件並未按照與查詢描述的相關性進行排序,這並不是我們最終想要的結果。那怎麽才能將尋找結果按相關性進行排序呢?首先,把查詢描述也視為一個由許多片語組成的短小文件,那麽查詢描述與對應文件的相關性問題就轉變成了文件之間的相關性問題。毫無疑問,文件主題近似程度高的,其相關性必然強;文件主題近似程度低的,其相關性必然弱。那進一步思考一下,什麽又是決定文件間相關性的主要因素?想必讀者都讀過或寫過論文,是否留意到每篇論文都有「關鍵字」這一項?「關鍵字」是能夠反映論文主題的詞或片語。也就是說,論文中每個詞對論文主題思維的表達程度是不同的。換個說法,文件中的每個詞對其主題思維表達的加權是不同的,正是這些不同加權的詞組成了文件的主題。
有兩個主要因素會影響一個詞在文件中的重要性。一是詞頻率(Term Frequency,TF),表示一個詞在此文中出現的次數,它的值越大,說明這個詞越重要。二是文件頻率(Document Frequency,DF),表示多少文件中包含這個詞,它的值越大,說明這個詞越不重要。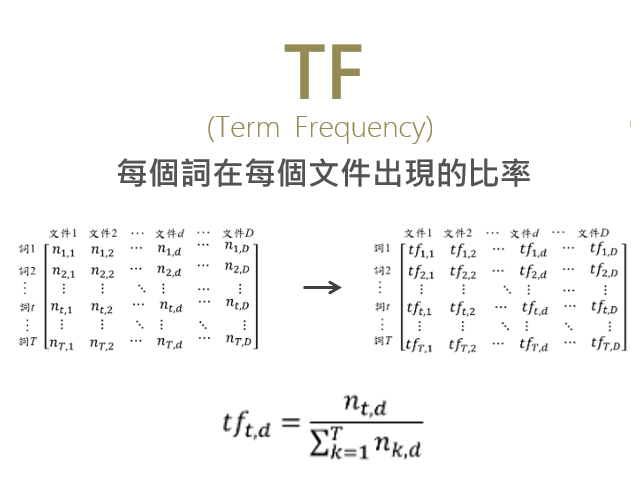


怎麽才能度量文件的相似度呢?第一步,把文件中每個詞的加權組成一個向量,Document Vector = (weight1, weight2, weightN)。把查詢描述也看作一個簡單的文件,將其中的每個詞的加權也組成一個向量,Query Vector = (weight1, weight2, weightN)。第二步,將所有查詢出的文件向量和查詢描述向量取並集,用並集元素的個數N統一各向量長度,如果一個文件中不包含某個詞,那麽該詞的加權為0。第三步,把所有統一後的向量放到一個N維空間中,每個詞是一維。
文件向量間存在一定的夾角。我們可以通過計算夾角余弦值的方法來表示它們之間的相似程度。因為夾角越小,余弦值越大,也就是說文件向量夾角的余弦值越接近,文件也越相近。
詞法分析和語言處理過程將一系列文字轉化為許多個詞,然後索引建立過程將這些詞生成詞典和倒排索引,索引寫程式將其寫入索引函數庫。
當用戶輸入查詢描述進行搜索時,首先進行詞法分析和語言處理,將查詢描述分解成一系列詞,然後將其輸入語法分析過程生成查詢語法樹。索引讀程式將反向索引表由索引函數庫讀取記憶體,搜索過程在反向索引表中尋找與查詢語法樹中每個詞一致的文件鏈結串列,並進行對應的布爾運算,獲得結果文件集。將結果
文件集與查詢描述的相關性進行排序,最後將結果傳回給用戶。
參考資料:深智數位《CV+AI自己動手完成圖像搜尋引擎》
【資料分析概念大全|認識文本分析】給我一段話,我告訴你重點在哪:對文本重點字詞加權的TF-IDF方法

